









Interessante que usamos o conceito de “aprendizado” no próprio nome das técnicas, como “Machine Learning” (ML) e “Deep Learning” (DL). A percepção que isso nos passa é que os algoritmos “aprendem” e imediatamente fazemos uma correlação com o nosso próprio processo de aprendizado. Assim, sem querer, acabamos intuindo que os sistemas de ML são entes inteligentes, que tem capacidade de aprender, como nós, em nossa vida, pessoal e profissional. Neste quarto artigo da série “Desmistificando a IA”, vamos discutir como os processos de “aprendizado” das máquinas são inteiramente diferentes do nosso.
Exemplificando com algoritmos de “aprendizado supervisionado”, vemos que eles gradualmente mudam os pesos dos seus parâmetros à medida que absorvem mais e mais dados dos data sets de treinamento. Com isso, começam a melhorar sua capacidade de reconhecimento de padrões e aumentam a assertividade de seus resultados. O resultado é que podem ter um nível de acerto muito bom em classificar uma imagem ou reconhecer padrões de textos, dentro do universo provido pelo data set de treinamento.
Em contraste com esse processo, nós humanos não somos limitados ao aprendizado limitado por data sets específicos, mas estamos abertos às experiências do mundo. Além disso, reconhecemos figuras e objetos, mesmo quando vimos anteriormente poucos exemplos. As crianças também não aprendem passivamente. Elas fazem perguntas e questionamentos o tempo todo e a partir daí conseguem inferir abstrações e conexões entre conceitos. Em resumo, elas aos poucos exploram o mundo, sem fronteiras artificiais.
Além disso, as máquinas não aprendem por conta ou vontade própria. Para criar um data set de treinamento houve muito esforço humano prévio em coletar, fazer curadoria e rotular os dados, bem como projetar as diversas características da arquitetura do sistema, como as escolhas dos próprios algoritmos, as variáveis que serão usadas e a profundidade das camadas da rede. Sim, os sistemas de ML e DL demandam volumes muito grandes de dados para obterem precisão adequada. E, na prática, somos nós humanos que fornecemos esses dados, como as fotos ou textos que disponibilizamos nas redes sociais e mecanismos de busca.
Alguns complexos sistemas de DL enfrentam muitas dificuldades, como os que controlam os veículos que se pretendem ser autônomos. Esses algoritmos precisam reconhecer com precisão as faixas de uma rodovia, sinais de trânsito, outros veículos e obstáculos diversos, como ciclistas, pedestres e animais. E precisam, além de identificar se os obstáculos estão em movimento, reconhecê-los em diversas condições climáticas, como chuva, nevasca e nevoeiro, tanto de dia como de noite.
Para isso, é necessário um imenso volume de dados, coletados por câmeras nos próprios veículos, que rodam milhões de quilômetros para melhorarem seu treinamento. Mas os usuários dirigindo esses veículos não podem rotular tudo que é registrado pelas câmeras, o que faz as empresas contratarem muita mão de obra barata para essa tarefa. Cada hora de rodagem do veículo demanda centenas de horas de trabalho, principalmente humano, para converter os dados brutos coletados em informações úteis para o “aprendizado” dos algoritmos. Vale a pena ler o artigo “Self-driving cars prove to be labour-intensive for humans” para termos uma ideia do que é necessário.
Temos, claro, tecnologias que ajudam, como a criação de dados sintéticos, mas existem situações como a “cauda longa” que precisa ser visualizada pelos algoritmos para que ele consiga funcionar com precisão. Cauda longa é um fenômeno que ocorre para cada motorista, muito raramente, mas, que no todo acaba ocorrendo com frequência. Os algoritmos precisam saber sair dessas situações.
Por exemplo, quando um humano está dirigindo em uma estrada, pode ser que na sua frente aconteça uma colisão entre um carro e uma vaca, coisa que ele nunca viu antes. Mas, pelo contexto e capacidade humana de reagir a situações insólitas, ele sabe o que fazer, como frear ou desviar. O algoritmo precisa ser treinado na situação, para ser capaz de reconhecer o padrão e a partir daí agir. Uma situação interessante pode ser vista nesse texto “This One Image Destroys Tesla’s Self-Driving Car Fantasy”.
Isso mostra que o problema dos veículos autônomos é muito complexo. Dirigir um veículo já é uma tarefa complexa, mesmo para um ser humano, pois envolve muitas subtarefas e inputs simultâneos, além de constantemente estarmos diante de eventos inesperados, como um cachorro atravessando uma rua. O trânsito é um cenário onde as situações insólitas e inesperadas acontecem com frequência, mas que são difíceis de serem replicadas em dados de treinamento.
Essa complexidade faz com que o hype otimista tenha que cair na real e agora espera-se que precisemos de pelo menos mais uns 20 anos para que a tecnologia de veículos completamente autônomos se torne realidade e seja usada comumente. Claro que nós humanos cometemos erros. Mas temos uma diferença fundamental que é senso comum.
Claro que nós humanos cometemos erros. Mas temos uma diferença fundamental que é senso comum
Nós usamos o senso comum com relação a objetos e como eles tendem a se comportar, e usamos constantemente essa capacidade nas nossas decisões. Nós interagimos socialmente com outros humanos e quando em situações de cruzamentos, sem semáforos, as comunicações não verbais entre dois motoristas resolvem a situação de quem vai primeiro. Como as máquinas não tem senso comum, dependem basicamente do reconhecimento de padrões em seus algoritmos.
Essa imensa diferença no processo de aprendizado entre nós e as máquinas é que gera uma incompreensão grande quanto aos resultados que a máquina pode gerar. Por exemplo, um algoritmo usado para reconhecer se aparece um animal ou não em uma imagem, pode correlacionar, baseado no que “aprendeu” com seu data set de treinamento, que o animal está sempre no foco da fotografia e o fundo, a natureza, muitas vezes aparece desfocada. Assim, quando a natureza for o foco, o sistema pode considerar que é um animal. Na verdade, o algoritmo não aprendeu a reconhecer animais, mas sim a usar “dicas” como fundo desfocado para saber se a foto tem ou não um animal. Nosso bom senso, nessa hora, é que faz a diferença.
Um problema sério no treinamento do algoritmo é a geração de vieses, embutidos quando o data set é “overfitted” ou seja, tem uma maior intensidade de dados de um tipo em detrimento de outros. Imaginemos um sistema de reconhecimento facial, que foi treinado basicamente com imagens de pessoas caucasianas. Ao se defrontar com um asiático, ele não vai, obviamente, analisar os padrões da imagem com os que reconheceu previamente pode gerar situações inconvenientes, como no exemplo abaixo.
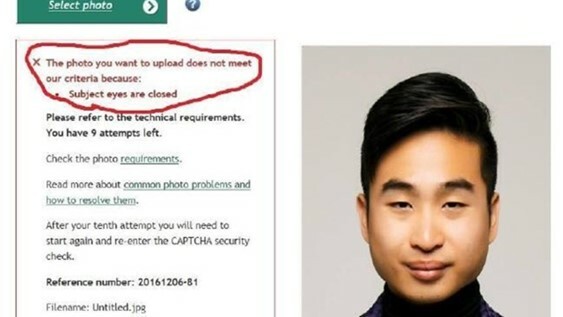
Muitas vezes, a dificuldade de compreender como o algoritmo chega a uma decisão, faz com que tenhamos que contornar o problema de forma pouco satisfatória. O famoso caso do Google em associar imagens de pessoas de pele negra à gorilas foi resolvido eliminando as fotos de gorilas do data set de treinamento: “Google ‘fixed’ its racist algorithm by removing gorillas from its image-labeling tech”.
Esse aspecto é um importante questionamento dos modelos de ML/DL: a complexidade dos algoritmos e a nossa incapacidade de sabermos por que determinada decisão foi tomada por eles. São verdadeiras “black boxes”. Eles chegam a uma decisão por meio de uma sequência de operações matemáticas, propagadas pelas diversas camadas das redes neurais. Isso pode, em determinadas situações, chegar a bilhões de operações aritméticas.
Entender essa complexa “calculeira” está além da capacidade humana. O artigo “ The Dark Secret at the Heart of AI” é bem didático e mostra como é, pelo menos, até agora, impossível desvendar essa caixa preta. Existem muitos esforços nessa área e um campo de pesquisa chamado “Explainable AI” se concentra em como desvendá-las. Mas, ainda está engatinhando.
Nós humanos também não conseguimos ler a mente de outro. Entretanto, podemos pedir explicações e ao recebê-las, podemos acreditar nelas ou não. Mas o importante é que podemos questionar e validar o processo de raciocínio lógico que alguém adotou para chegar à determinada decisão, baseada inclusive na nossa experiência do mundo e senso comum.
Uma vez que as máquinas não entendem o que estão vendo, podem ser enganadas e gerar resultados estapafúrdios. Alterações em pixels, às vezes imperceptíveis aos humanos, podem afetar o reconhecimento de padrões. O artigo “Google’s AI thinks this turtle looks like a gun, which is a problem” mostra como isso pode ser feito. Por exemplo, na imagem abaixo, as figuras (a) foram corretamente identificadas, mas as figuras (b) foram alteradas e passaram ser reconhecidas pelo algoritmo como avestruz.

Esse é um problema que pode trazer sérias implicações, dependendo do tipo de aplicação dos sistemas de IA. Por exemplo, uma alteração indevida em imagens médicas pode mudar o diagnóstico e provocar sérias consequências. Vale a pena ler o estudo “Adversarial attack vulnerability of medical image analysis systems: Unexplored factors ”, que aborda esses riscos.
A diferença fundamental entre as máquinas e humanos é a compreensão. A máquina vê, mas não entende. Na figura acima, não confundiríamos um cachorro com uma avestruz. A razão é que ao contrário dos algoritmos, que tem como visão do mundo apenas seu data set de treinamento, nós vamos muito além. Nós temos percepção do tamanho dos objetos, sua função, seu cheiro e consistência, ou seja, a compreensão do mundo em que ele e nós estamos imersos. Isso faz parte da nossa cognição, essencial para a sobrevivência da espécie.
Passada a euforia e entusiasmo, aprendemos que os sistemas de ML/DL têm muitas limitações. As ideias grandiosas que a IA substituiria os humanos na maioria das profissões simplesmente nem chegou perto de acontecer. As técnicas de IA que predominam hoje, ML/DL, são apenas uma “narrow AI”, ou seja, são capazes de executar apenas uma única função.
Pode ser melhor que um humano nessa tarefa, como jogar xadrez, mas não tem a mínima ideia do que é um jogo de xadrez e o que significa vencer um jogo. Mas claro que sistemas que fazem bem determinadas tarefas são muito úteis e podem aumentar a eficiência dos processos. Podem também nos ajudar a criar novos modelos de negócio. Aliás, sem algoritmos de IA não conseguiríamos ter um mecanismo de busca tão eficiente como o do Google.
Cezar Taurion é VP de Inovação da CiaTécnica Consulting, e Partner/Head de Digital Transformation da Kick Corporate Ventures. Membro do conselho de inovação de diversas empresas e mentor e investidor em startups de IA. É autor de nove livros que abordam assuntos como Transformação Digital, Inovação, Big Data e Tecnologias Emergentes. Professor convidado da Fundação Dom Cabral, PUC-RJ e PUC-RS.










")







")

