









A Inteligência Artificial (IA) já existe há muitas décadas e nos anos 1970 e 1980 do século passado vimos muitas experimentações dos chamados sistemas especialistas. Não deram muito certo e por algumas décadas a IA ficou adormecida. Mas, os avanços em termos de capacidade computacional, disponibilidade de dados e evolução dos algoritmos permite que agora consigamos construir soluções de IA cada vez mais sofisticadas, abrangendo aplicações que a computação programática, aquela da codificação passo a passo, não conseguiam.
Mas o que é IA? Uma definição sucinta pode ser simplesmente: “IA é um termo geral que se refere a hardware ou software que exibe comportamento que parece inteligente”. O diferencial da IA em relação à programação tradicional é que, na IA, o ônus de encontrar soluções para problemas complexos é transferido do programador para o programa. O atual entusiasmo em relação à IA é devido a um conjunto de técnicas chamadas aprendizado de máquina (Machine Learning ou ML), que vem evoluindo muito rapidamente.
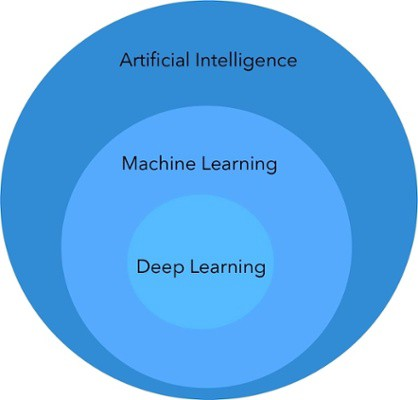
ML é um subconjunto da IA. Todo aprendizado de máquina é IA, mas nem toda IA é aprendizado de máquina. Usando ML, ao invés de codificar regras para os programas seguirem, os programadores permitem que os programas aprendam com os dados que acessam. Uma frase do cientistas de computação e pioneiro da IA, Arthur Samuel, sintetiza o conceito do aprendizado de máquina: é o “campo de estudo que dá aos computadores a capacidade de aprender sem serem explicitamente programados”.
Os algoritmos de ML aprendem por meio de treinamento: o algoritmo recebe, como entrada, dados de treinamento, cujas saídas geralmente são conhecidas antecipadamente (o que chamamos de 'aprendizado supervisionado'). O algoritmo processa estes dados de entrada para produzir uma previsão ou recomendação. A diferença entre o resultado gerado pelo algoritmo e a resposta correta é então determinada. Se o resultado ou saída do algoritmo estiver incorreta, temos que rever e ajustar a função de processamento no algoritmo.
Inicialmente, os resultados de um algoritmo de ML serão ruins. No entanto, à medida que mais e mais dados de treinamento são fornecidos, as previsões do sistema de ML tendem a se tornar altamente precisas. Em algoritmos de ML a qualidade de suas previsões melhora com a experiência. Normalmente, quanto mais dados relevantes são fornecidos para treinamento, mais eficazes serão suas previsões.
Existem diversas abordagens para aplicação de ML. Cada uma usa formas diferentes de arquitetura algorítmica para otimizar previsões com base nos dados de entrada. Por exemplo, “Random Forests” criam “florestas” de árvores de decisão para otimizar previsões. Segundo o Kaggle, estes algoritmos são usados por quase metade dos cientistas de dados. Também temos “Bayesian networks” que usam abordagens probabilísticas para analisar variáveis e os relacionamentos entre elas. E SVM (Support Vector Machines) onde a partir de exemplos categorizados, ele cria modelos para atribuir novas entradas a uma das categorias. Um quarto dos cientistas de dados emprega SVM (Kaggle).
As limitações dos algoritmos de ML aparecem quando demandamos determinadas tarefas como entender a fala ou reconhecer objetos nas imagens. Por exemplo, é difícil escrever um programa que identifique imagens de cães. Os cães variam significativamente em sua aparência visual. Essas variações são muito amplas para serem descritas por um conjunto de regras que permitam uma classificação correta. Mesmo que um conjunto exaustivo de regras puder ser criado, a abordagem não seria escalável e seria necessário um novo conjunto de regras para cada tipo de objeto que quiséssemos classificar.

Para resolver este problema surgiram mais recentemente as técnicas de aprendizado profundo ou Deep Learning (DL). O aprendizado profundo é um subconjunto de aprendizado de máquina. Todo aprendizado profundo é aprendizado de máquina, mas nem todo aprendizado de máquina é aprendizado profundo.
O aprendizado profundo é valioso porque transfere uma carga adicional, o processo de extração de recursos, do programador para o programa. Como ele faz isso? Nós humanos aprendemos a executar tarefas sutis, como reconhecer objetos e entender a fala, não seguindo regras explícitas, mas através da prática e do feedback. Quando crianças, nós experimentamos o mundo (vemos um cachorro), fazemos uma previsão ("olha lá um cachorro") e recebemos feedback. Nós, seres humanos aprendemos através do treinamento.
O aprendizado profundo funciona recriando o mecanismo do cérebro no software. Com o aprendizado profundo, modelamos o cérebro, não o mundo. Para criar um algoritmo de DL, os desenvolvedores criam neurônios artificiais, funções matemáticas ou calculadoras baseadas em software que aproximam grosseiramente a função dos neurônios no cérebro.
Neurônios artificiais são conectados para formar uma rede neural. A rede recebe uma entrada (como a imagem de um cachorro), extrai recursos e oferece uma determinação. Se a saída da rede neural estiver incorreta, as conexões entre os neurônios se ajustam para alterar suas previsões futuras. Inicialmente, as previsões da rede frequentemente estarão incorretas. No entanto, como a rede é alimentada com muitos exemplos (potencialmente milhões), as conexões entre os neurônios se tornam mais e mais afinadas.
Assim, ao analisar novos exemplos, a rede neural artificial fará determinações mais corretas. Normalmente, as redes neurais são treinadas expondo-as a um grande número de exemplos etiquetados ou rotulados. À medida que os erros são detectados, os pesos das conexões entre os neurônios se ajustam para melhorar os resultados. Quando o processo de otimização é repetido extensivamente, o sistema começa a avaliar imagens não identificadas, sem ajuda humana. Ou seja, começa a aprender sozinho.
O aprendizado profundo não é adequado para todos os problemas. Normalmente, exige grandes conjuntos de dados para treinamento
Os algoritmos de DL estão por trás de feitos como veículos autônomos, tradução em tempo real, Echo da Amazon, AlphaGo, Alpha Zero e outras aplicações sofisticadas que temos visto recentemente. Claro, o aprendizado profundo não é adequado para todos os problemas. Normalmente, o DL exige grandes conjuntos de dados para treinamento. O treinamento e a operação de uma rede neural também exigem um imenso poder de processamento.
Além disso, também é difícil identificar como uma rede neural desenvolve uma previsão específica, o chamado desafio da “explainability” que é mostrar como determinada resposta foi produzida. O uso de redes neurais demanda mais sofisticação dos profissionais de ML. É necessária uma habilidade significativa para projetar e otimizar uma rede neural. São necessárias várias etapas como estruturar a rede neural para uma aplicação específica; fornecer dados de treinamento adequados; ajustar a estrutura da rede de acordo com a sua evolução; e, muitas vezes, combinar várias abordagens para otimizar resultados.
IA é uma ferramenta poderosa. Recomendo assistir ao vídeo “Machine Learning: Living in the Age of AI", produzido pela WIRED Film”. É um vídeo de 40 minutos que mostra de forma bem didática como IA já está inserida no nosso dia a dia.
Mas, antes de investir tempo e dinheiro em IA, você precisa de uma estratégia para orientar sua utilização. Sem uma estratégia, a IA se tornará um custo adicional que não fornecerá um adequado retorno do investimento. As iniciativas de IA não devem ser feitas pelo modismo (“todos estão fazendo”) mas com objetivos bem claros para resolução de problemas de negócio.
Não existem soluções “plug-and-play” que magicamente funcionam do nada, sem uma longa e exaustiva fase de treinamento do algoritmo aos seus dados
Esteja atento às suas limitações, e separe os mitos da realidade. Não existem soluções “plug-and-play” que magicamente funcionam do nada, sem uma, às vezes longa e exaustiva fase de treinamento do algoritmo aos seus dados; não esqueça que nem tudo pode e deve ser resolvido através da IA. Estude e se aprofunde nos conceitos, potencialidades e limitações da IA. Priorize seus projetos de IA baseados no valor a ser gerado e na sua viabilidade (existem dados para possibilitar treinamento do algoritmo?). Assegure-se que você tem equipe preparada (“ML engineers” não são colhidos em árvores). E reserve orçamento adequado. O treinamento dos algoritmos pode demandar muito tempo e a implementação do sistema pode demandar grandes recursos computacionais.
Nos projetos de IA garanta que as demandas de segurança, privacidade e ética estejam sendo adequadamente endereçadas, que os dados não embutem vieses que podem gerar mais dano que valor. E não esqueça que IA é uma solução embutida em algo maior, que provavelmente demandará modificações em processos de negócio.
À medida que você for obtendo experiência com projetos de IA vai aprender que os prazos para suas iniciativas são muito mais incertos do que os que você está acostumado, como no desenvolvimento de software tradicional. Os sistemas de IA não podem ser desenvolvidos de forma linear, desenvolvidos de uma vez, testados e implantados.
Normalmente, são necessários vários ciclos de treinamento para identificar uma combinação adequada de dados, arquitetura de rede e 'hiperparâmetros' (as variáveis que definem como um sistema aprende). Essa dinâmica varia de acordo com o domínio e a natureza do problema e os dados disponíveis. Portanto, pode ser um desafio prever ou automatizar iniciativas de IA, a menos que sejam muito similares aos projetos que você já realizou anteriormente.
Além disso, precisamos ter confiança que não temos anomalias. Diferentemente da computação programática onde o software responde diretamente ao desenvolvedor que coloca todas as instruções em linhas de código e caso a resposta não seja correta, você depura e conserta o código, a IA interpreta dados com seus algoritmos e daí toma suas decisões.
Nos algoritmos não supervisionados, não sabemos se a resposta está certa ou errada, pois a resposta pode ser algo que nós humanos não havíamos percebido e a máquina identificou como um padrão e gerou sua decisão a partir desta constatação. A máquina pode gerar resultados surpreendentes, que nós jamais imaginaríamos.
Embora as escalas de tempo variem de acordo com o problema que você está abordando e os recursos reservados, é possível desenvolver um protótipo em dois ou três meses. Mas não esqueça que enquanto pode levar apenas alguns dias para desenvolver uma primeira versão de um sistema que oferece 50% de precisão, pode demorar semanas para melhorar o sistema para 80% de precisão, e muitos meses para atingir 95%. E talvez demore muito mais para melhorias incrementais adicionais, como passar para 98%.
Assim, defina desde o início os limites de precisão que serão adequados para a solução do problema. O tempo de desenvolvimento depende de diversas variáveis, como a possibilidade ou não de uso de APIs externas já disponíveis, proficiência da equipe no uso de frameworks de IA, uso de empresas especializadas em IA para reforçar a equipe interna, e a qualidade dos dados disponíveis. Os dois maiores desafios que você vai enfrentar são a escassez de talentos e a baixa qualidade dos dados corporativos. Sim, mesmo nas empresas que usam ERP descobrimos dados muito “sujos”.
Outro lembrete: manutenção. Para manter a inteligência do sistema de IA, teste regularmente os resultados com dados ativos, para garantir que os resultados continuem atendendo seus critérios de aceitação. Separe budget para futuras atualizações e reciclagem, e monitore sistematicamente a degradação do desempenho. À medida que sua empresa cresce ou muda o foco, os dados (incluindo dados de séries temporais e características do produto) evoluirão e se expandirão.
A reciclagem sistemática de seus sistemas deve ser um componente de sua estratégia de IA. Lembre-se de que a IA é uma capacidade, não um produto. Está sempre melhorando. Surgem novos algoritmos e as técnicas de IA que usamos hoje podem se tornar obsoletas em poucos anos.
E, finalmente, para sair do projeto inicial e disseminar IA na empresa precisa-se de alguns reforços. O primeiro é o apoio e engajamento da liderança, os C-level (e principalmente e CEO). Não esqueça que IA não sai de graça e demanda investimentos e comprometimentos de vários setores da empresa.
Sem apoio executivo você fica apenas com o projeto-piloto, o MVP da IA
Sem apoio executivo você fica apenas com o projeto-piloto, o MVP da IA. Para conseguir este apoio é necessário investimento em educação e evangelização do potencial da IA, bem como propostas sólidas de quais problemas de negócio a IA poderá resolver, e como.
Pense em IA fazendo parte das atividades normais do negócio. Uma empresa “AI powered” implica que a IA será disseminada na organização e seu uso será tão comum como hoje nos acostumamos a usar ERP no ambiente corporativo. Como você planejou o uso do ERP na década passada, planeje IA para os próximos anos.
*Cezar Taurion é Partner e Head of Digital Transformation da Kick Corporate Ventures e presidente do i2a2 (Instituto de Inteligência Artificial Aplicada). É autor de nove livros que abordam assuntos como Transformação Digital, Inovação, Big Data e Tecnologias Emergentes. Professor convidado da Fundação Dom Cabral. Antes, foi professor do MBA em Gestão Estratégica da TI pela FGV-RJ e da cadeira de Empreendedorismo na Internet pelo MBI da NCE/UFRJ.










")








")
